Hello! I created this thread to discuss the resource usage of the node runner software for Radix nodes.
I’ve always encountered high disk I/O usage by the Checkpointer thread that I’ve managed to mitigate somehow by increasing -Xms and -Xmx arguments in the Enviroment file.
The higher the value, the lower the disk usage is. On a node with 64 GB of RAM, setting both arguments to 30G almost fixes the problem, bringing my average disk write to 4 MB/s.
On another node with less RAM I am unable to set -Xms and -Xmx to 30G and the average disk writes are much higher, reaching more than 10MB/s.
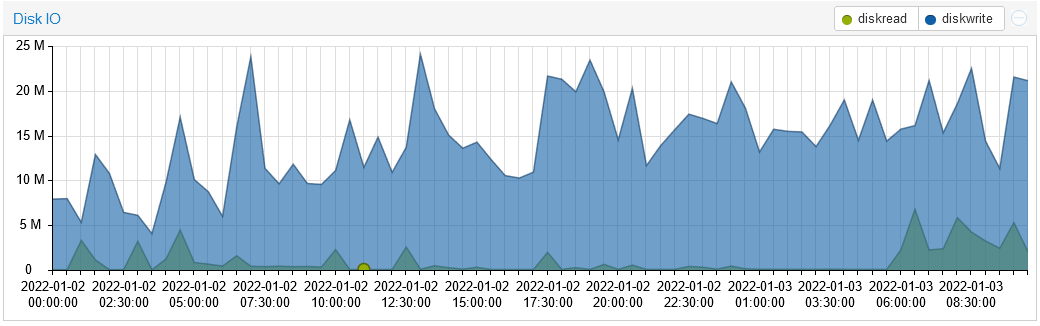
This is with -Xms and -Xmx to 20G. Lowering the value increases disk writes even more, with a default setting of 8G this is what I was getting:
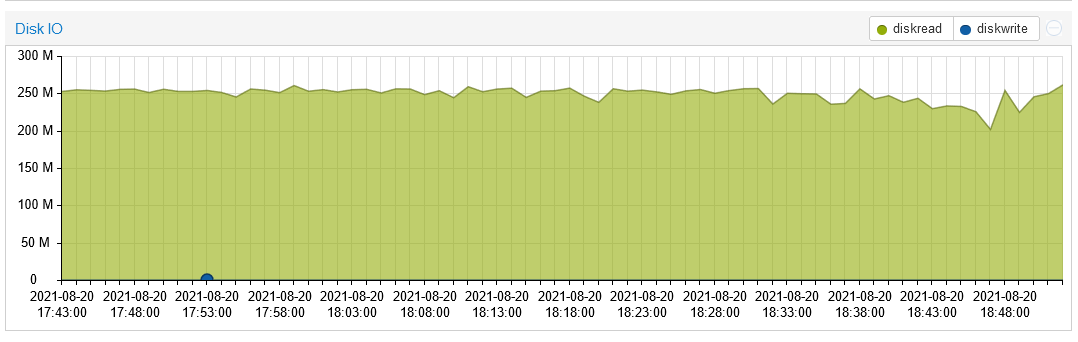

Those are all writes even though my hypervisor is reporting them as reads (old bug). Obviously this was destroying my SSDs pretty quickly.
I’ve found some helpful information on Berkeley DBs and how its cache works (start here) and apparently 20% of the JVM memory is reserved for cache (je.maxMemoryPercent has a default value of 20%).
I tried calculating the optimal memory size using this guide and got the following:
I ran java -cp je-18.3.12.jar com.sleepycat.je.util.DbPrintLog -S -h /data/ and then java -cp je-18.3.12.jar com.sleepycat.je.util.DbCacheSize -records 85002586 -key 20 -data 63 using the data I got from the first command.
=== Environment Cache Overhead ===
3,158,773 minimum bytes
To account for JE daemon operation, record locks, HA network connections, etc,
a larger amount is needed in practice.
=== Database Cache Size ===
Number of Bytes Description
--------------- -----------
4,169,465,456 Internal nodes only
13,529,308,256 Internal nodes and leaf nodes
For further information see the DbCacheSize javadoc.
So, to cache all the internal nodes only I would need 4GB of memory, which considering the default je.maxMemoryPercent of 20%, amounts to 20~GB of -Xmx for the JVM.
As you can see comparing the two screenshots, increasing Java’s memory 20G helped reduce the writes, but they’re still very high compared to what Radix Team and others are seeing on their nodes.
I also followed this tip from Stuart and set je.log.fileMax=1073741824 and je.checkpointer.bytesInterval=250000000.
I tried doubling the Checkpointer’s bytesInterval value and it increased the time between each write spike, but also increased the maximum disk write during those spikes.
The issue goes away by making the node a fullnode instead of a validator node; writes pretty much disappear or drop to some KB/s. More info in this GitHub issue.
Please feel free to discuss other performance optimization or resource usage concerns you have in this thread.